
CI/CD for Machine Learning: Best Practices to Automate Your ML Workflow
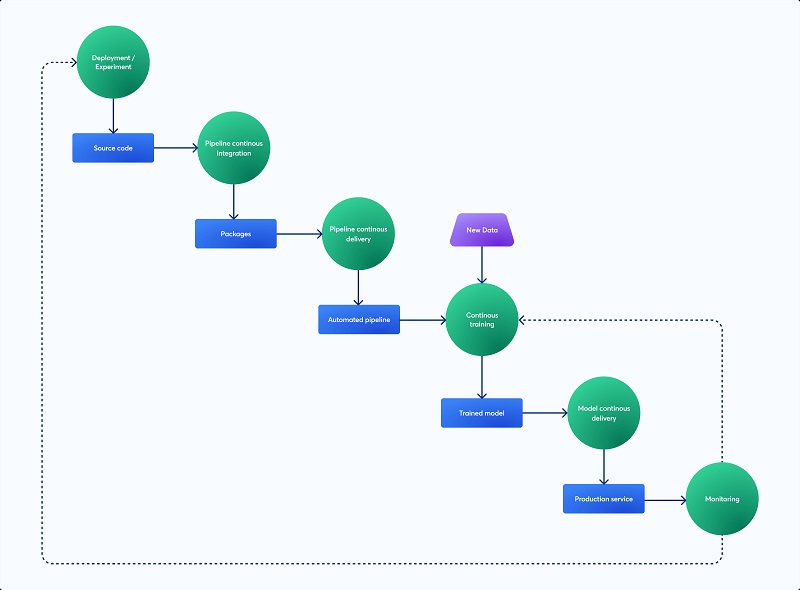
Although machine learning (ML) has quickly changed many industries, putting ML models into production and keeping them up to date may be very difficult. A strong framework for handling the intricacies of the ML model lifecycle is provided by conventional software development techniques such as Continuous Integration and Continuous Deployment (CI/CD). Teams may automate the development, testing, deployment, and monitoring of machine learning models by implementing CI/CD for ML (MLOps). This reduces the possibility of errors in production, improves model performance, and speeds up iteration cycles. This article describes best practices for efficiently automating your machine learning process and examines the fundamentals of CI/CD in the context of machine learning.
Implementing Data and Model Version Control
Strict version control is the cornerstone of any strong CI/CD pipeline for machine learning. ML models, in contrast to conventional software, are intricately linked to the training data. As a result, version control needs to cover data and models in addition to code. To monitor changes in your datasets, use programs such as Git LFS (Large File Storage) or DVC (Data Version Control). To handle several iterations of your trained models, use model registries like MLflow or a specialized object storage system. This enables straightforward lineage tracing from data to model, easy rollback to earlier iterations, and reproducibility of tests.
Automating Model Training and Evaluation
An essential part of a CI/CD pipeline for machine learning is automated model training and evaluation. This entails creating scripts that, in response to code modifications, the availability of new data, or predetermined intervals, automatically start model training pipelines. To choreograph these activities, use frameworks such as Apache Airflow or Kubeflow. To evaluate model performance on validation datasets, incorporate automated evaluation measures into your workflow, such as F1-score, recall, accuracy, and precision. what are mlops best practices is key to establishing precise acceptance standards for model performance and automatically identifying models that fall short of them.
Establishing Robust Testing and Validation Procedures
To guarantee the robustness and dependability of your ML models, extensive testing is essential. This goes beyond using a held-out validation set to assess model performance. Conduct several kinds of testing, such as:
Unit tests: Check that specific parts of your code, like data pre-treatment operations or model scoring logic, are valid.
Integration tests: Verify that the various components of your machine learning pipeline, including feature engineering, data ingestion, and model training, function as a cohesive unit.
Embracing Continuous Improvement
CI/CD for ML is a continual process of continuous improvement rather than a one-time deployment. Review your pipeline on a regular basis, note areas that could use improvement, and take production monitoring input into account. To continuously enhance model performance, experiment with various model topologies, hyper parameters, and training data. Adopt logging and monitoring to learn more about model behaviour and spot possible problems before they affect consumers.













